- Materialize a GSM8K evaluator and dataset with
pytest - Kick off a Reinforcement Fine-Tuning (RFT) job for a small base model
- Track accuracy improvements by re-running the evaluator
Running the GSM8K tutorial in Google Colab requires a Google account with billing enabled (credit card on file). Fireworks usage also bills against your account once you supply
FIREWORKS_API_KEY. 👉 Run the GSM8K Fine-tuning ColabPrerequisites
- Python 3.10+
- Local Python environment with Jupyter support (VS Code, JupyterLab, or classic notebook)
FIREWORKS_API_KEYwith permissions to launch RFT jobs (stored in your shell or.env)- Basic familiarity with GSM8K-style math reasoning tasks
Install dependencies
Install the latest
eval-protocol SDK directly from the main branch and make sure pytest is on the path. Upgrade pip first to avoid resolver issues.Download evaluation assets
Download the evaluation assets we will use to kick off the job. Copy the GSM8K pytest script and sample dataset into a working directory (here Expected output:
gsm8k_artifacts/). The snippet below is safe to run inside a notebook cell or standalone script and ensures the files land where later steps expect them.tutorial/download_gsm8k_assets.py
Run the GSM8K evaluation locally
Execute the evaluation that materializes the evaluator and dataset. Point the test at the artifacts folder you created in the previous step.This command discovers and runs your 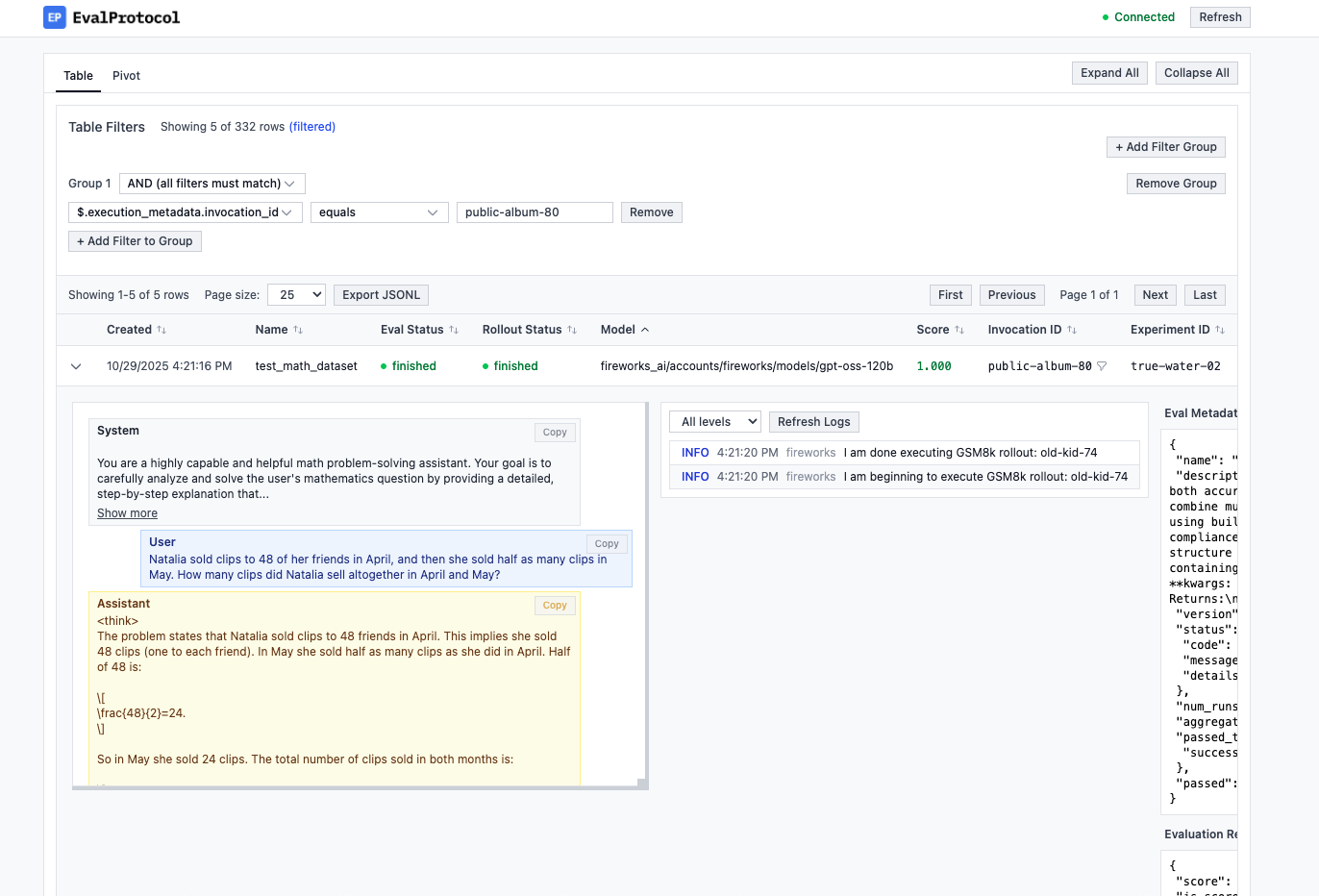
@evaluation_test with pytest.You should see log output for each rollout and navigate to http://localhost:8000 to see the Eval Protocol UI and inspect results.Set FIREWORKS_API_KEY
Store your Fireworks API key in the environment so the CLI can authenticate. The command below keeps the key confined to the current shell session.Alternatively, load it from a secrets manager or
.env file if your workflow already manages credentials securely.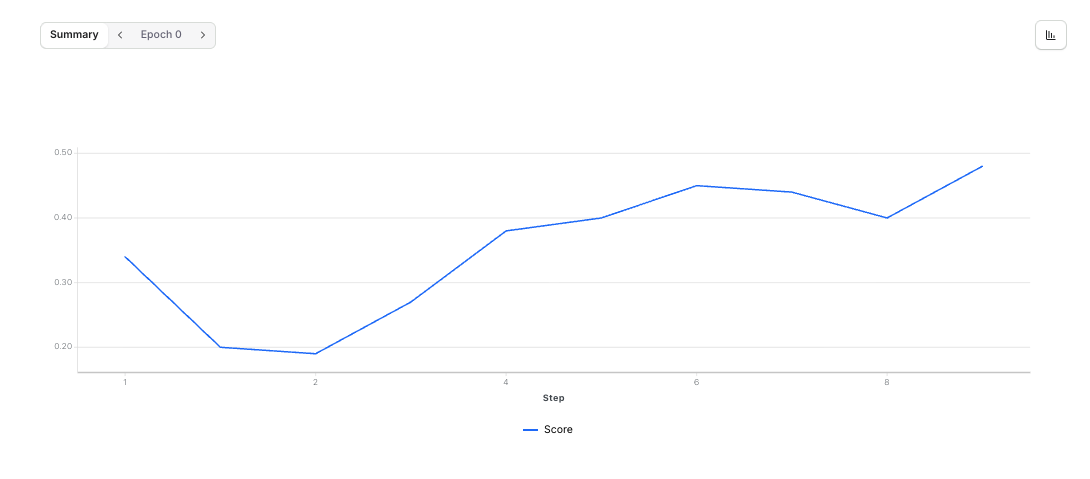
Track accuracy over time
- Re-run the
ep local-testcommand periodically to evaluate the latest checkpoint against the GSM8K slice. - Adjust reward shaping or parsing logic inside
test_pytest_math_example.pyto fit your formatting expectations. - Swap in a custom dataset JSONL by editing the local artifact or passing
--dataset-jsonlwhen creating the RFT job.
What’s happening under the hood
- The evaluation tests a small GSM8K slice with a numeric-check reward and registers an evaluator plus dataset with your local API.
- The
create rftcommand wires those resources into a Reinforcement Fine-Tuning job for the specified base model. - As training progresses, evaluation scores reflect improved accuracy on the held-out set, letting you iterate quickly before scaling up.
Next steps
- Parameterize base models and dataset paths in scripts or notebooks to make repeated experiments easier.
- Automate the evaluation loop in CI so new policies are validated before deployment.
- Promote successful evaluators and datasets to shared registries once the workflow is stable.