Introduction
This repo demonstrates building an SVG generation agent using reinforcement fine tuning, with the parts:- Eval Protocol - Orchestrates the rollout execution and evaluation framework
- Vercel Typescript Server - Remote server that handles SVG code generation rollouts
- Fireworks RFT - Reinforcement fine tuning trainer
Quick Start
Installation
- Create a Fireworks account: https://app.fireworks.ai/account/home
- Clone the quickstart repo: https://github.com/eval-protocol/quickstart
- Install Eval Protocol:
- Environment Setup:
env.example file is located in the evaluator/ directory. Make a copy of it in the same directory, name it .env, and fill in your API keys:
evaluator/.env with your API keys:
Running Locally
Terminal 1 - Start the local UI server to view results:@evaluation_test with pytest. In this case, it builds an image and runs the test in Docker, because a Dockerfile is present.
The test automatically uses our Vercel remote server:
- If your evaluation setup has custom dependencies, for example Chromium, you will need containerize it using
Dockerfile- Then, when you run
ep local-test, we will build an image and run pytest inside Docker
- Then, when you run
- If not,
ep local-testwill just run pytest on your host machine- You can also ignore the
Dockerfileand run on the host Python env usingep local-test --ignore-docker
- You can also ignore the
Expected Test Output:
Navigate to http://localhost:8000 to see the Eval Protocol UI.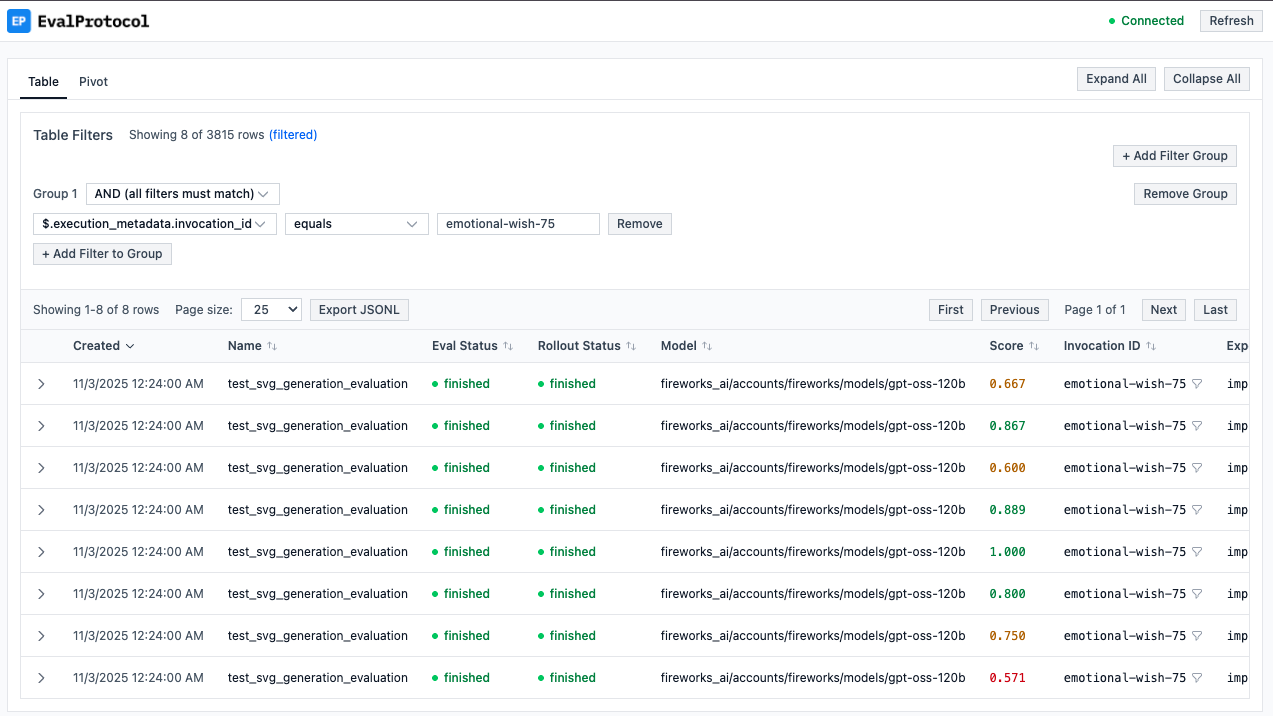
Single Command to Train
To kickoff training, simply do:- 🔐 Uploads Secrets - Automatically reads your
.envfile and uploads API keys as Fireworks secrets - 📦 Uploads Evaluator - Packages and uploads your evaluation code
- ⏳ Waits for Build - Polls evaluator status every 10 seconds until ACTIVE (timeout: 10 minutes)
- 📊 Creates Dataset - Automatically uploads your
svgbench_dataset.jsonl - 🚀 Launches RFT Job - Starts reinforcement fine-tuning with your evaluator
Configuration & Troubleshooting
Training Parameters: We use Eval Protocol’s default values for training parameters (batch size, epochs, learning rate, LoRA rank, accelerator count, etc.). For a complete list of available RFT flags you can customize, see Fireworks RFT Command Documentation. Changing Evaluators: If you’ve made changes to your evaluator code and want to upload a new version:Monitor Training Progress
After successful job creation, you’ll see:Training Results
After successful training, you should see performance improvements reflected in the training metrics: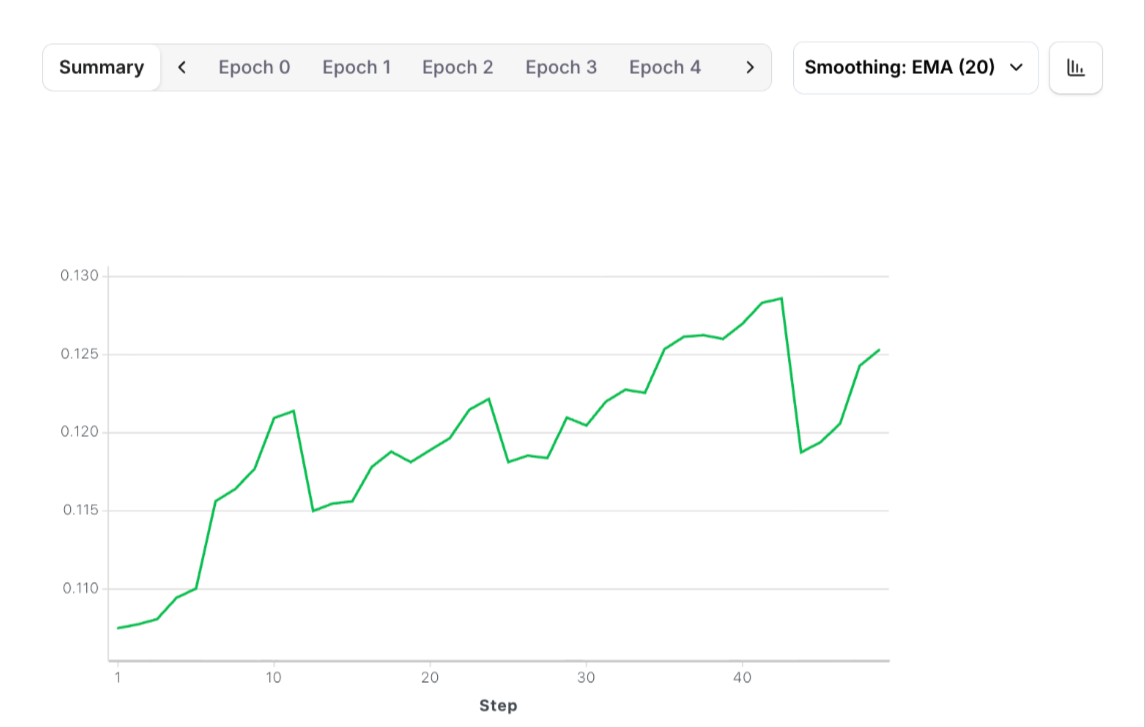
SVG Quality Improvement
You can inspect individual rollouts to see the dramatic improvement in SVG generation quality. Below is a comparison between the first epoch and the final 8th epoch: Before (1st Epoch):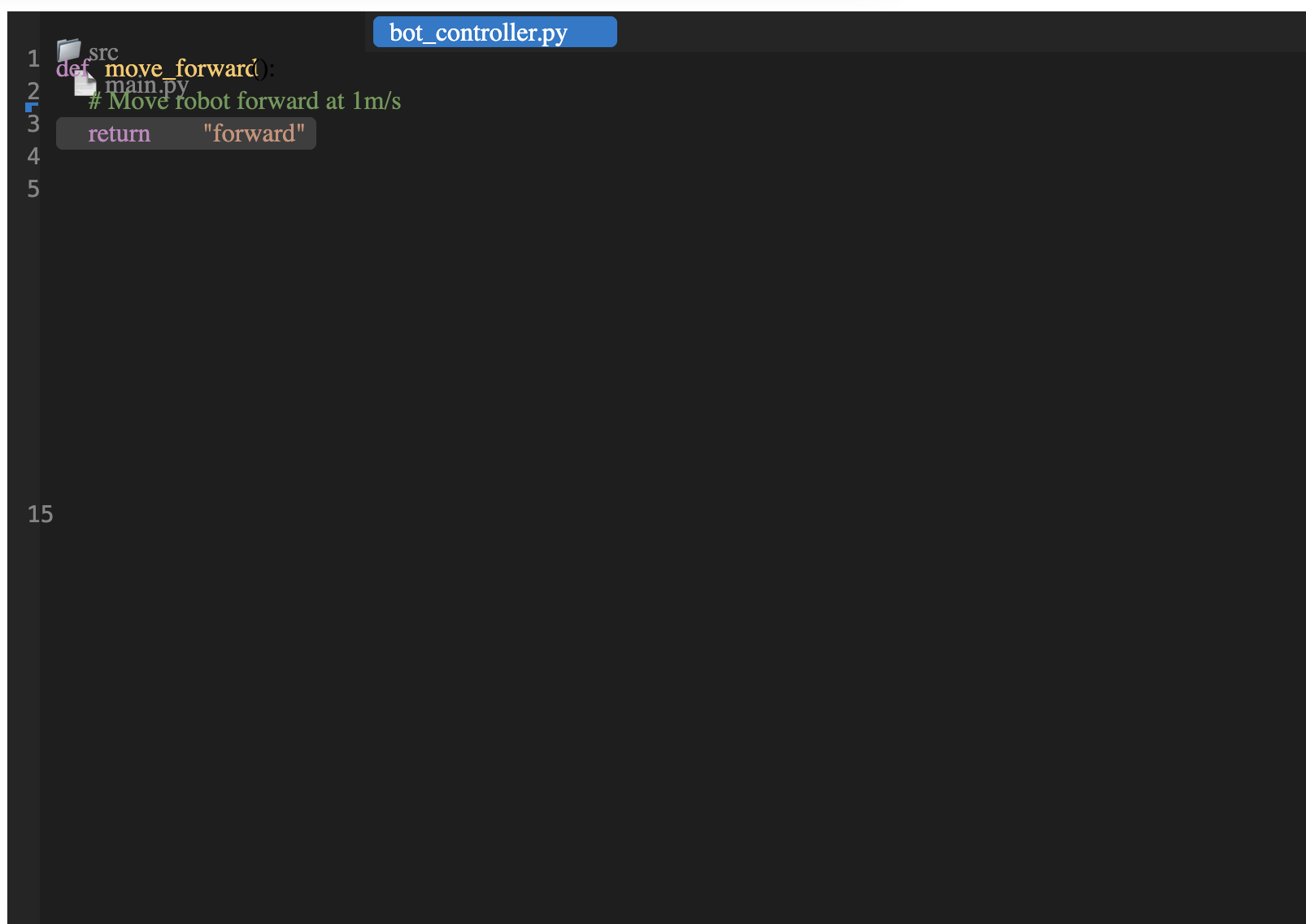
Debugging Tips
When your training is running, you have several powerful tools to debug and monitor your rollouts:Rollout Overview
Clicking on any Epoch or Step in the training dashboard, then clicking the table icon to the right, will show you a comprehensive table of all rollouts. It’s a good high-level overview to see if any rollouts failed and for what reason.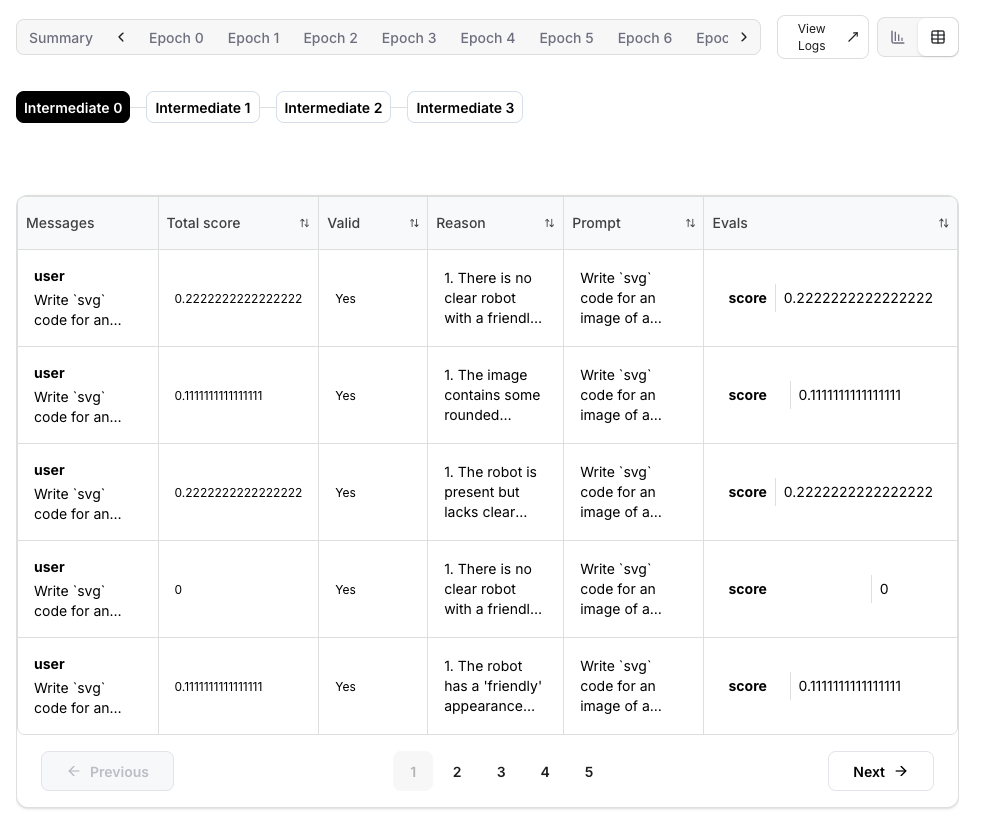
Individual Rollout Details
If you click on a specific row in the rollout table, you can see exactly what the prompt was and how the model responded. You can even copy and paste out the SVG code generated and render it yourself to see what the model did. This is how we got the results above in the before and after comparison.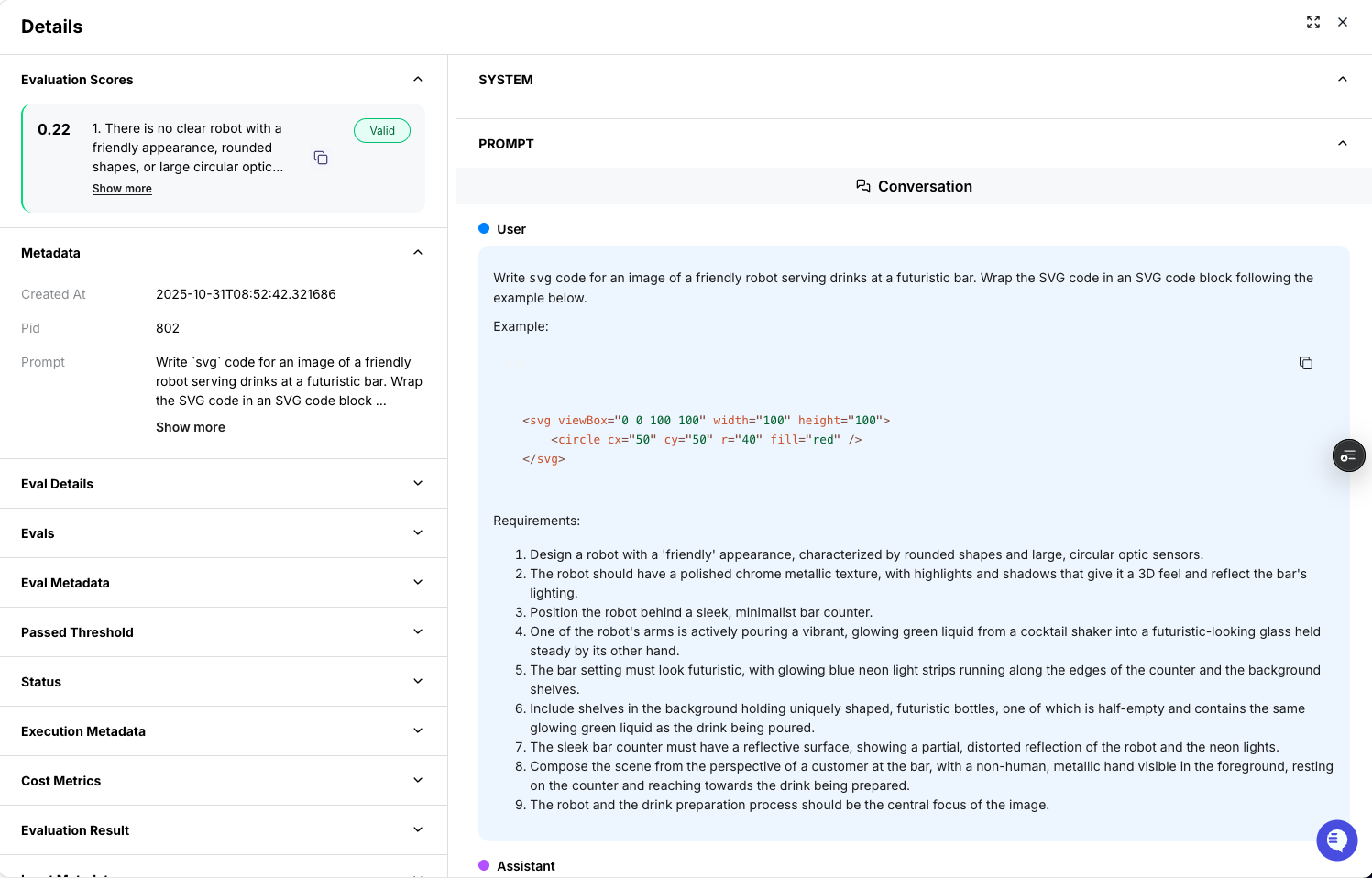
Live Log Streaming
Clicking on View Logs takes you to a page of logs being streamed in. Here, you can see precisely what errors are happening to the rollouts. This is useful to debug and fix any issues with your rollouts.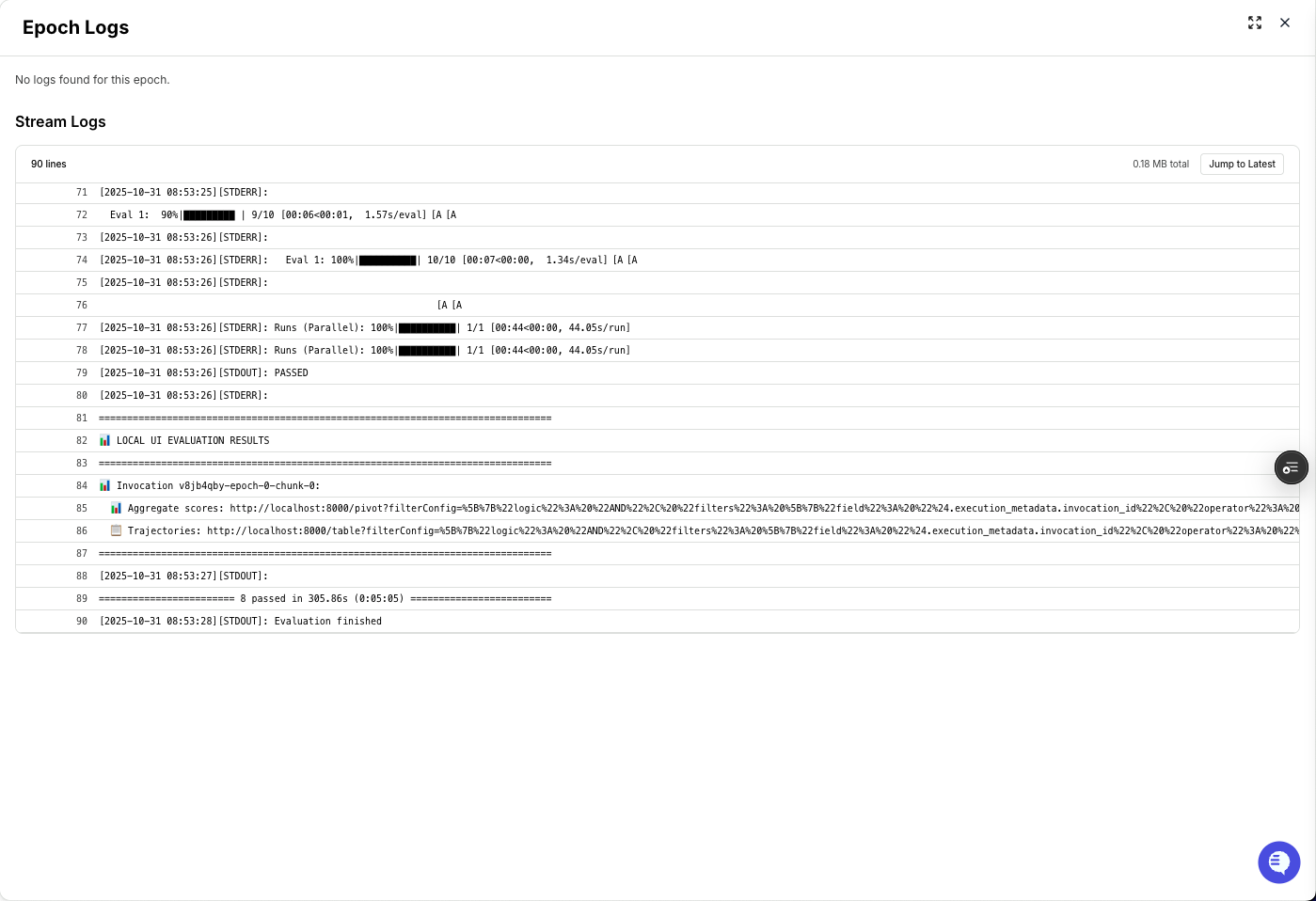
Contact Us / Learn More
- Discord Server. Come talk to us in the #eval-protocol channel!
- Eval Protocol Documentation
- Remote Rollout Processor Tutorial
- SVGBench Dataset - The original benchmark this project is based on
- Fireworks AI Platform
Appendix
How Remote Rollout Processing Works
Eval Protocol enables reinforcement learning that meets you where you are. Instead of forcing you to rewrite your agent in a specific framework, you can implement a lightweight remote server wherever your codebase and infrastructure already live. Your remote server is only responsible for:- Executing rollouts - Run your agent logic (in this case, SVG generation from text prompts)
- Logging to tracing - Send structured logs to
tracing.fireworks.aifor evaluation (see the below linked docs for more information)
📖 Learn More: For a complete deep-dive into Remote Rollout Processing, see the Remote Rollout Processor Tutorial.
Local Development Server
remote_base_url to point to the local server you just started:
See Vercel CLI documentation for more information on local development.