eval-protocol provides an out-of-the-box rollout processor for LangGraph.
LangGraphRolloutProcessor
This orchestrates rollouts for LangGraph apps so you only need to pass a
graph factory function and eval-protocol will handle running your experiments
against your dataset. The factory accepts a typed RolloutProcessorConfig.
Graph Factory
To supply a LangGraph app for evaluation, define a factory function that accepts aRolloutProcessorConfig and returns a compiled graph with .ainvoke.
In this example, we assume you have a build_simple_graph function that creates a
LangGraph app using a given model.
completion_params in RolloutProcessorConfig to get model name and other
parameters, then construct your LangGraph app accordingly.
Simple Graph Example
Our simple LangGraph app uses LangChain-native messages and a single node that calls the configured model.Writing the Eval
Every eval ineval-protocol expects an input dataset of type List[EvaluationRow].
For this example, a small JSONL dataset of prompts is used and adapted into EvaluationRows via
an adapter function. The rollout processor handles converting EvaluationRow.messages to
LangChain messages and applies the model output back to the row.
Generating a Score
Evals ineval-protocol return a score between 0.0 and 1.0. This simple
example scores whether the assistant replied.
Reasoning Model Example
You can also evaluate reasoning models likegpt-oss-120b and control reasoning via
reasoning_effort.
Passing reasoning_effort
Use completion_params to pass reasoning_effort values like
“low”, “medium”, or “high”.
Running the Evaluation
- CLI
- VSCode
Creating a Leaderboard
To compare different models, add multiple entries tocompletion_params and set num_runs to
get robust evaluation across runs.
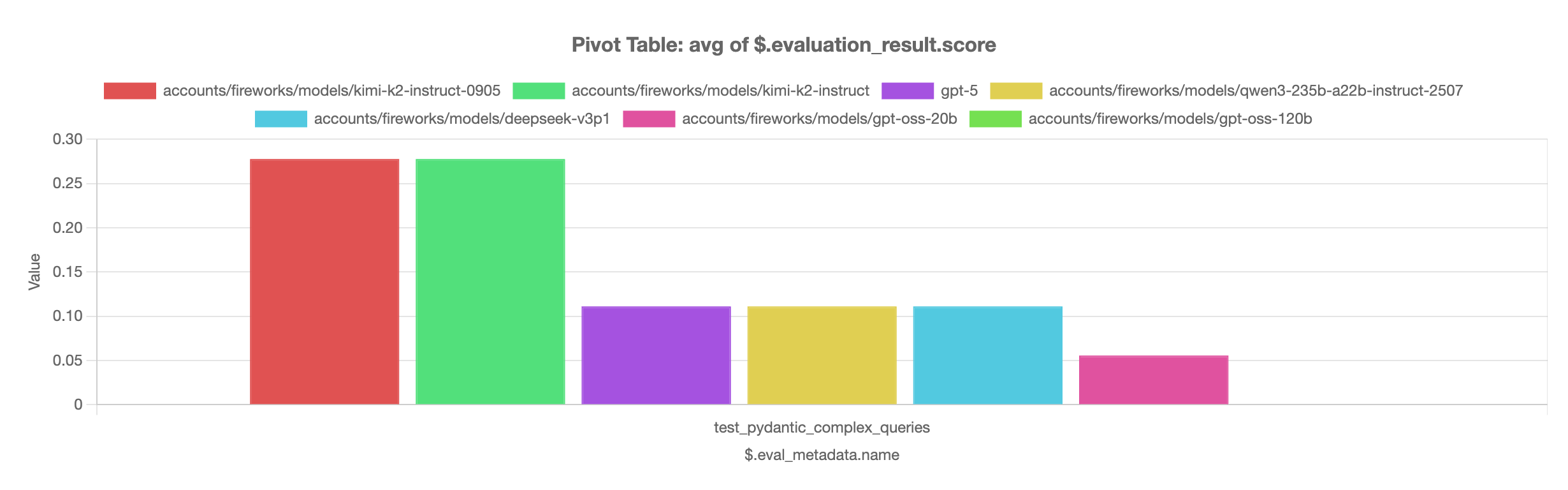
Example leaderboard showing model performance comparison in the Pivot View.