- OpenEnv environments via
OpenEnvRolloutProcessor(BrowserGym, Echo, TextArena, Atari-style games, coding envs, and more). - Other Eval Protocol tests that expose token IDs and rewards through a rollout processor (for example
SingleTurnRolloutProcessor), with more trainers and environments added over time.
Why Use Eval Protocol for TRL Training?
Eval Protocol handles the rollouts:- Environment management (Docker containers, lifecycle)
- Rollout execution (observation → LLM → action → environment)
- Task Rotation
- Reward collection and formatting
- Concurrency control
- GRPO optimization
- Model updates
- Gradient computation
- Checkpointing
- Define how to build prompts from observations
- Define how to parse LLM outputs into actions
- Configure your environment and training parameters
Architecture
At a high level, TRL and Eval Protocol split responsibilities:- TRL (GRPOTrainer) owns the training loop: it calls a
rollout_func, computes losses and gradients, and updates the model. - Eval Protocol owns the rollout loop: it turns TRL prompts into
EvaluationRows, runs environments (for example viaOpenEnvRolloutProcessor), calls your model through vLLM, and returns token IDs and rewards. - Environments (OpenEnv or other Eval Protocol tests) are configured once in a
@evaluation_testfile, which Eval Protocol reuses both for offline evals and for TRL training.
rollout_func created by create_openenv_vllm_rollout_func into GRPOTrainer, each training step looks like:
- TRL calls
rollout_func(prompts, trainer). - Eval Protocol builds
EvaluationRows and runs rollouts using the configured rollout processor. - The
@evaluation_testis executed to computeevaluation_result.scorefor each row. - Eval Protocol returns token IDs and scores to TRL, which computes gradients and updates the model.
Prerequisites
1. Install Dependencies
2. (Optional) Build local BrowserGym Docker images
You only need this step if you want to run BrowserGym locally in Docker.If you are using environments from the Hugging Face Hub (for example
EchoEnv.from_hub(...)) or a remote HTTP server/Space via base_url=..., you can skip this section.
3. Start vLLM Server
Start TRL’s vLLM server on a separate GPU:Use a separate GPU for vLLM inference (GPU 0) and training (GPU 1) for best performance.
4. Setup Environment (BrowserGym + MiniWoB++ example)
This step is only required if you are training on MiniWoB++ BrowserGym tasks locally. For other environments (Echo, TextArena, remote BrowserGym on the hub/Spaces), you can skip it. For MiniWoB++ tasks, serve the HTML locally:Reusing Eval Protocol tests with TRL
The biggest value of this integration is that you can reuse your existing@evaluation_test files for training:
- The Eval Protocol test owns the environment wiring (for example
OpenEnvRolloutProcessor+ BrowserGym/Echo/TextArena config). - The test body owns the reward logic (it sets
row.evaluation_result). - TRL just points at that test by module path and reuses both environment and scoring.
create_openenv_vllm_rollout_func helper:
- Looks up your
@evaluation_testvia itsenv_path(for example"tests.pytest.test_openenv_browsergym_eval"). - Reuses the attached
OpenEnvRolloutProcessorconfiguration (env client, tasks, env vars, timeouts, etc.). - Runs the test function itself to populate
row.evaluation_result. - Returns a
rollout_functhat produces token IDs and rewards in the format TRL expects.
- Add a new environment by writing a single
@evaluation_test. - Use the same test in:
- Offline evals and dashboards (
ep logs). - TRL training, by pointing
env_pathat that test.
- Offline evals and dashboards (
Inspecting TRL rollouts in the Logs UI
Because all rollouts go through Eval Protocol, every TRL training step that uses this integration is also visible in the Eval Protocol Logs UI:- Each call to
rollout_funccreates one or moreEvaluationRows, just like a normal eval run. - Those rows are logged with
EvalMetadataso you can filter by eval name, time, and status. - You can inspect the full message history, actions, rewards, and token usage for each rollout.
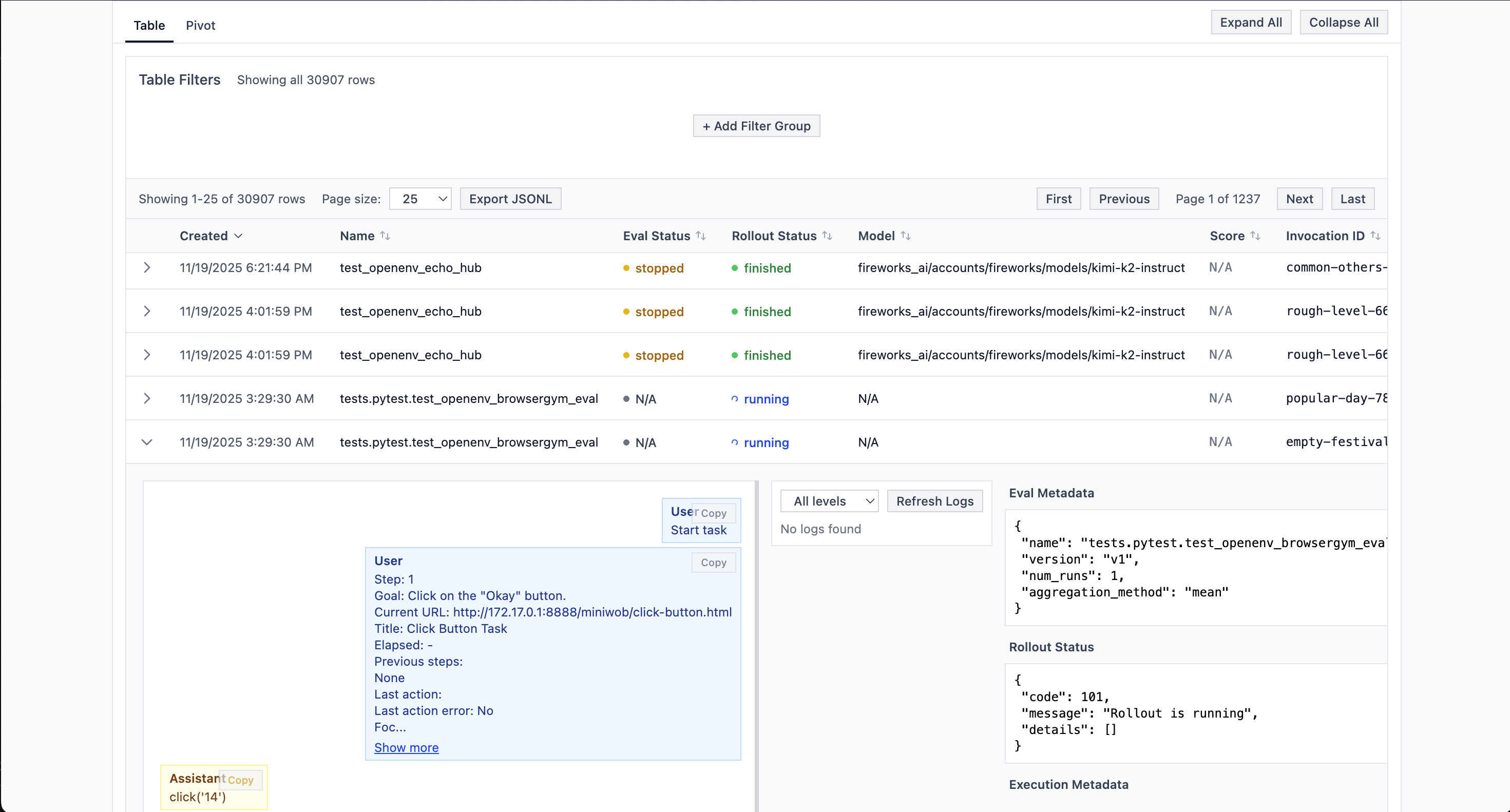
Quick Start: BrowserGym + TRL (reusing an eval test)
Below is a minimal example that trains on BrowserGym MiniWoB++ tasks by reusing an existing Eval Protocol test (tests.pytest.test_openenv_browsergym_eval) that already configures OpenEnvRolloutProcessor and reward logic.
train_browsergym_trl.py
Running the Training
How It Works
When you callcreate_openenv_vllm_rollout_func(), eval-protocol creates a function that TRL’s trainer will call during training. Here’s what happens:
- TRL calls
rollout_func(prompts, trainer)with a batch of prompts - eval-protocol creates evaluation rows from the prompts (one row per generation)
- OpenEnvRolloutProcessor executes rollouts:
- Creates Docker containers for environments
- Runs the agent loop: observation → LLM → action → environment
- Collects rewards and tokens from each step
- eval-protocol formats results into TRL-compatible format (token IDs + rewards)
- TRL uses the results to compute policy gradients and update the model
Configuration Parameters
Rollout Function Parameters
OpenEnv environment client class (e.g.,
BrowserGymEnv, TextArenaEnv)Function that converts observation to text prompt for the LLM
Function that converts LLM text output to environment action
URL of the TRL vLLM server
Model name on the vLLM server
List of tasks to rotate through during training
Environment variable name for task selection (required when
tasks is provided)Environment variables to pass to Docker containers
Docker image for the environment
Maximum steps per episode
LLM sampling parameters (temperature, max_tokens, etc.)
Maximum concurrent rollouts (defaults to batch size)
GRPO Training Parameters
Batch size per device
Number of rollouts per prompt (must divide evenly into batch size)
Learning rate for training
Sampling temperature for generation
Maximum tokens per generation
Must be
True to use vLLM serverMust be
"server" to use separate vLLM serverURL of the vLLM server
Best Practices
1. Use Instruct Models
Use instruction-tuned models (e.g.,Qwen2.5-7B-Instruct) rather than base models for better instruction following:
2. Separate GPUs for Inference and Training
Run vLLM inference on one GPU and training on another:3. Use LoRA for Efficiency
LoRA reduces memory usage and speeds up training:4. Balance Batch Size and Generations
Ensureper_device_train_batch_size is divisible by num_generations:
5. Monitor Rewards
Track average rewards to ensure learning progress:Troubleshooting
vLLM Server Not Found
Error:Connection refused to http://localhost:8000
Solution: Ensure vLLM server is running:
Docker Container Fails
Error:RuntimeError: Failed to start Docker container
Solution:
- Verify Docker image exists:
docker images | grep browsergym-env - Check container logs:
docker logs <container-id> - Ensure environment variables are correct
Out of Memory
Error:CUDA out of memory
Solution:
- Use LoRA instead of full fine-tuning
- Reduce
per_device_train_batch_size - Reduce
max_completion_length - Enable
gradient_checkpointing=True
Low Rewards
If rewards remain low:- Verify your reward function is correct
- Check that environment tasks are solvable
- Review LLM outputs in rollout logs
- Adjust temperature (lower = more deterministic)
- Improve prompt engineering