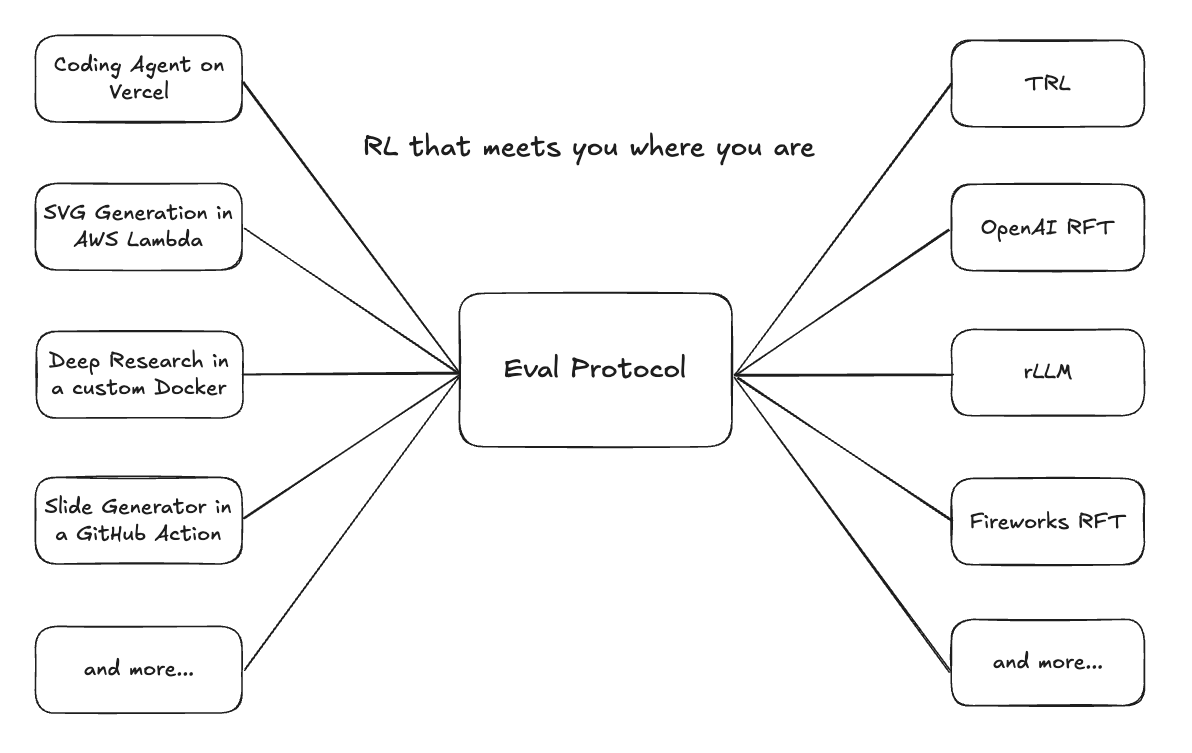
- Expose Your Agent Through a Simple API Wrap your existing agent (Python, TypeScript, Docker, etc.) in a simple HTTP service using EP’s rollout interface. EP handles the rollout orchestration, metadata passing, and trace storage automatically.
- Connect With Any Trainer Once your agent speaks the EP standard, it can be fine-tuned or evaluated with any supported trainer — Fireworks RFT, TRL, Unsloth, or your own — with no environment rewrites.
Who This Is For
- Applied AI teams adding RL to existing production agents.
- Research engineers experimenting with fine-tuning complex, multi-turn or tool-using agents.
- MLOps teams building reproducible, language-agnostic rollout pipelines.