Examples
Image Multi-Turn Eval with Per-Step Rewards (Lunar Lander)
If you haven’t read through Multi-turn eval (per-step rewards) yet, we recommend checking that out first as this tutorial builds on those foundational concepts.
You can find the complete code for this example at test_lunar_lander.py.
Understanding the Lunar Lander Environment
Lunar Lander is a classic physics-based RL environment where an agent controls a spacecraft landing on the moon, requiring both visual understanding and precise control.- Action Space:
Discrete(4)- NOTHING (0), FIRE_LEFT (1), FIRE_MAIN (2), FIRE_RIGHT (3) - Observation Space:
Box(8)- [x, y, velocity_x, velocity_y, angle, angular_velocity, leg1_contact, leg2_contact] - Visual Component: 400x600 RGB rendered frames showing the lander, moon surface, and landing flags
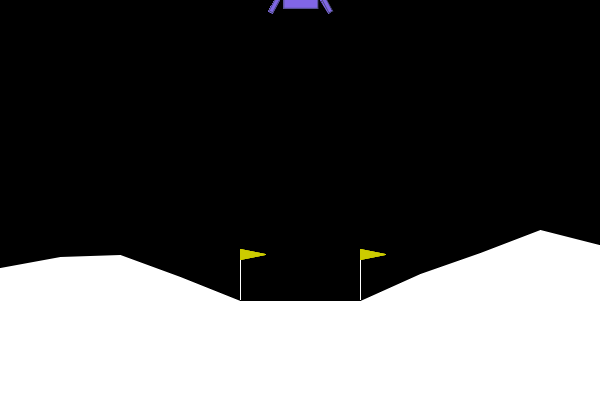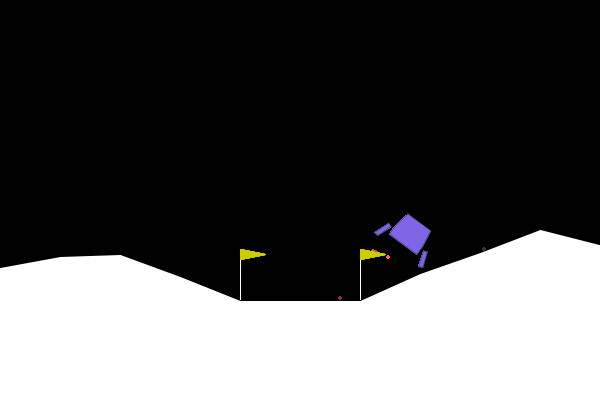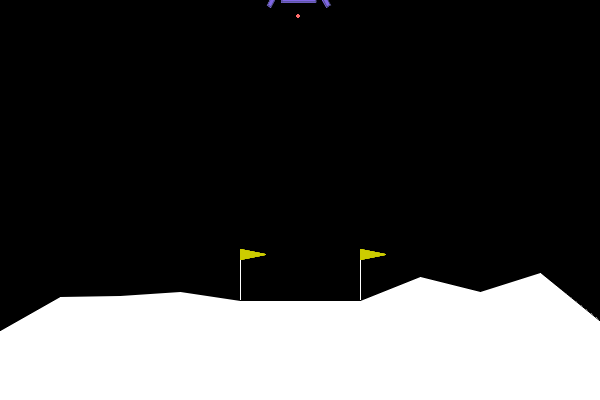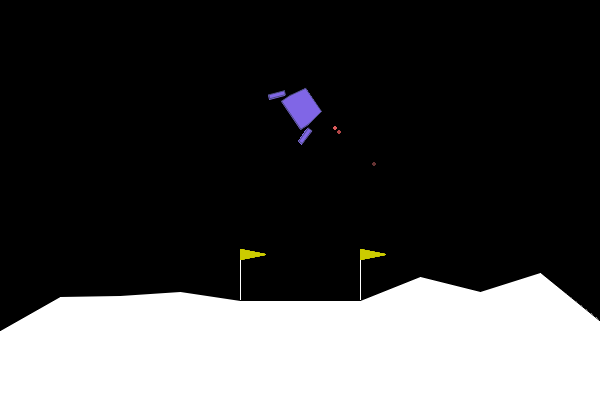 Complex Reward Structure: Unlike Frozen Lake’s sparse binary rewards, Lunar Lander provides detailed per-step feedback:
Complex Reward Structure: Unlike Frozen Lake’s sparse binary rewards, Lunar Lander provides detailed per-step feedback:
- Distance to landing pad (closer = better)
- Velocity penalties (slower = better)
- Angle penalties (more horizontal = better)
- +10 points per leg touching ground
- Fuel consumption penalties (-0.03 for side engines, -0.3 for main engine)
- Final outcome: +100 for successful landing, -100 for crash
Understanding the Dataset Structure
The Lunar Lander dataset demonstrates multimodal prompting - agents must analyze both numerical state and visual information to make decisions.Example Dataset Entry
- Visual Analysis Required: “describe what is in the image attached”
- State Analysis: Both numerical state data and visual information
- Tool Integration: Structured interaction through
lander_actiontool
Test Harness Architecture
The architecture is similar to Frozen Lake’s in the sense that we again extendMcpGym and create an EnvironmentAdapter, but there are some key differences.
MCP Server: LunarLanderMcp
TheLunarLanderMcp class extends McpGym with visual rendering capabilities in format_observation:
Environment Adapter: LunarLanderAdapter
TheLunarLanderAdapter acts as an adapter to the Gymnasium library’s implementation of the LunarLander game, which includes both the physics simulation and visual rendering:
Pytest Implementation
Step 1: Dataset Adapter
Step 2: Test Configuration
- Vision Model Required:
gpt-4.1or other vision-capable models - Same Rollout Processor: Reuses
default_mcp_gym_rollout_processorfrom Frozen Lake, demonstrating framework generalization across text and visual environments - Episode Management:
steps=15is not enough for the Lunar Lander game to complete, it likely would take hundreds of steps.
Step 3: Trajectory Evaluation
As defined by the game, a success is if a score of 200 or over is achieved, which is then converted to 1 or 0 to signify a pass or fail in our Pytest setup.Conclusion
This Lunar Lander tutorial showcases eval-protocol’s multimodal evaluation capabilities, demonstrating how the framework seamlessly handles complex visual RL environments while maintaining the same architectural patterns established with text-based evaluations. The key innovation is the dual-stream observation system: agents receive both structured numerical data and visual frames, enabling sophisticated multimodal reasoning about physics, control, and spatial relationships. The per-step reward structure in Lunar Lander is particularly valuable for training data generation. Unlike Frozen Lake’s sparse rewards, every frame provides rich feedback about landing performance, fuel efficiency, and trajectory optimization. This creates dense multimodal training signals that can inform visual RL algorithms, multimodal fine-tuning approaches, and hybrid training systems that combine visual understanding with control policy learning. In the future, we hope to extend this work to frontier LLM use-cases like browser-use agents. Most importantly, this example demonstrates eval-protocol’s modality-agnostic design. The samedefault_mcp_gym_rollout_processor, pytest patterns, and evaluation infrastructure work seamlessly across text-based grid worlds and complex visual physics simulations. This unified approach enables practitioners to build comprehensive evaluation suites spanning the full spectrum of AI capabilities—from language understanding to visual reasoning to real-time control—all within a single, consistent framework.